Roboflow SupervisionのDataset処理機能を使用して、自作のデータセットをレビューしてみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
Roboflowから提供されている、Supervisionは、容易に導入でき、非常に強力なコンピュータビジョンツールとなっています。
https://supervision.roboflow.com/latest/
Supervisionを使用すると、各種のライブラリ(Inference、Ultralytics、Transformers)で推論した結果を、数行のコードで簡単に可視化できます。
import cv2
import supervision as sv
from ultralytics import YOLO
# ultralyticsによる推論
model = YOLO("yolov8n.pt")
image = cv2.imread(<SOURCE_IMAGE_PATH>)
results = model(image)[0]
detections = sv.Detections.from_ultralytics(results)
# アノテーション追加
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated_image = box_annotator.annotate(
scene=image, detections=detections)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections)
# 表示
cv2.imshow("view", annotated_image)
cv2.waitKey(0)

また、Supervisionにはデータセット処理機能も備わっています。
今回は、この機能 Process Datasets を使用して、自作のデータセットのレビューを行ってみました。
2 作業環境
作業はJetpack 6.0をセットアップした、Jetson AGX Orin で行いました。
環境構築は、dustynv/jetson-inferenceをベースとしたDockerコンテナを作成しています。
Dockerfile
FROM dustynv/jetson-inference:r36.3.0
RUN apt-get update
RUN apt-get install -y python3-tk
RUN pip install matplotlib pyyaml tqdm pandas psutil
RUN pip install segment_anything
RUN pip install ultralytics --no-deps
RUN pip install scipy seaborn gitpython
RUN pip install supervision
$ docker build -t supervision:latest .
$ docker images | grep supervision
supervision latest f51d8b6d904b About a minute ago 15.3GB
dockerstart.shで、/homeをローカルにマウントして、作成したイメージを起動しています。
$ cat dockerstart.sh
xhost +
docker run -it --rm --runtime nvidia --shm-size=1g -v /tmp/.X11-unix:/tmp/.X11-unix -v $(pwd)/home:/home -e DISPLAY=:0 --network host supervision:latest
Suppervisionのバージョンは、0.25.0となっていました。
$ ./dockerstart.sh
# cd home
# pip list | grep super
supervision 0.25.0
3 データセットの処理
データセットを読み込んだり、操作したりする処理は、下記に紹介されています。
以下は、過去に作成したデータセットをレビューしている様子です。
(1) YOLO形式のデータセット配置する
# tree output_yolo
output_yolo/
├── data.yaml
├── train
│ ├── images
│ │ ├── xxxx.png
・・・略・・・
│ │ └── xxxx.png
│ ├── labels
│ │ ├── xxxx.txt
・・・略・・・
│ │ ├── xxxx.txt
│ └── labels.cache
└── valid
├── images
│ ├── yyyy.png
・・・略・・・
│ └── yyyy.png
├── labels
│ ├── yyyy.txt
・・・略・・・
│ └── yyyy.txt
└── labels.cache
(2) コード
import supervision as sv
import cv2
dataset = "output_yolo"
ds = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset}/train/images",
annotations_directory_path=f"{dataset}/train/labels",
data_yaml_path=f"{dataset}/data.yaml",
)
print(f"len:{len(ds)} classes:{ds.classes}")
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated_images = []
for i in range(16):
_, image, annotations = ds[i]
labels = [ds.classes[class_id] for class_id in annotations.class_id]
annotated_image = image.copy()
annotated_image = box_annotator.annotate(annotated_image, annotations)
annotated_image = label_annotator.annotate(annotated_image, annotations, labels)
annotated_images.append(annotated_image)
grid = sv.create_tiles(
annotated_images,
grid_size=(4, 5),
single_tile_size=(350, 350),
tile_padding_color=sv.Color.WHITE,
tile_margin_color=sv.Color.WHITE,
)
cv2.imshow("grid", grid)
cv2.waitKey(0)
(3) 表示
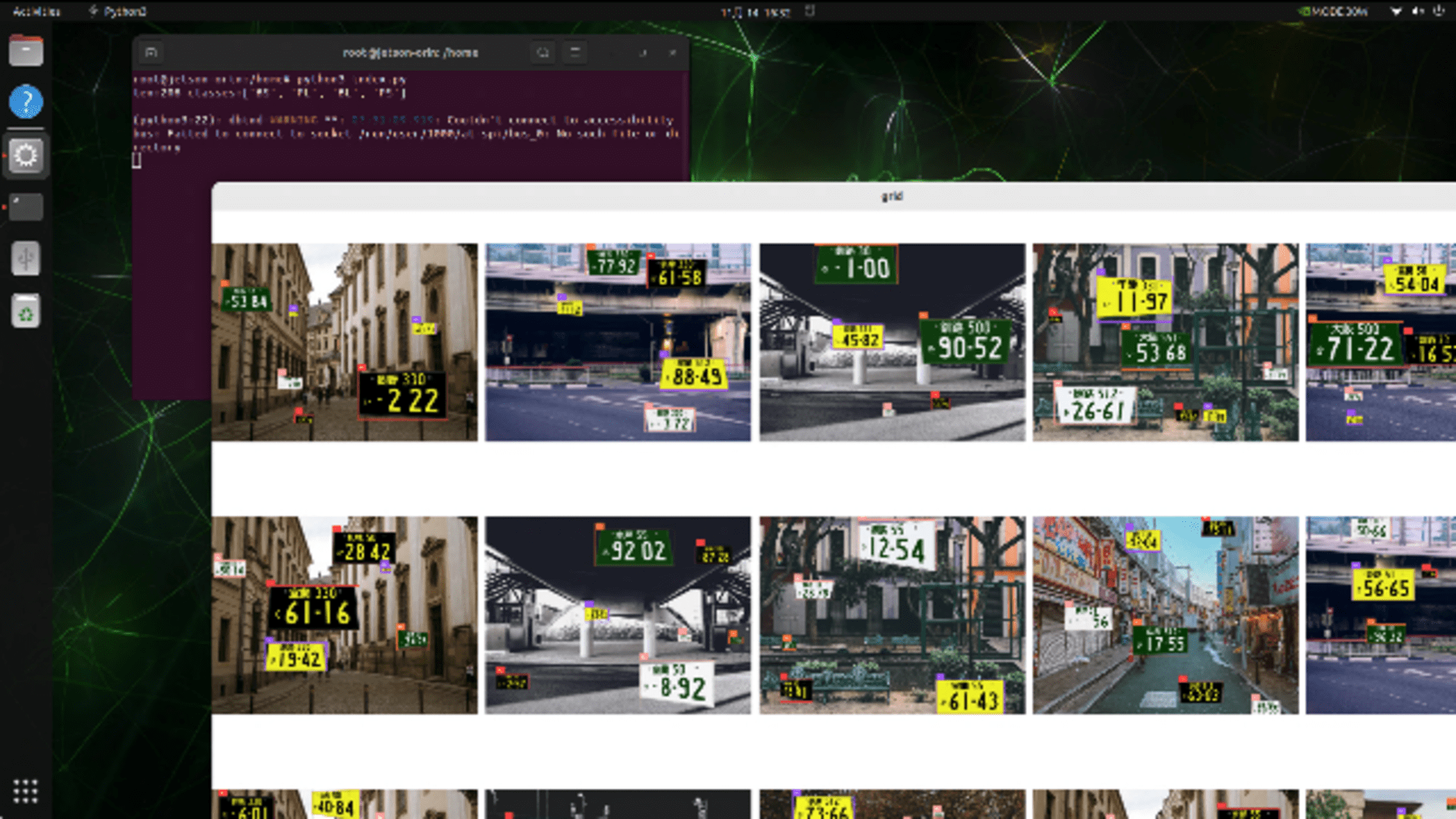
ナンバープレート検出で作成したデータセットを表示している様子です。

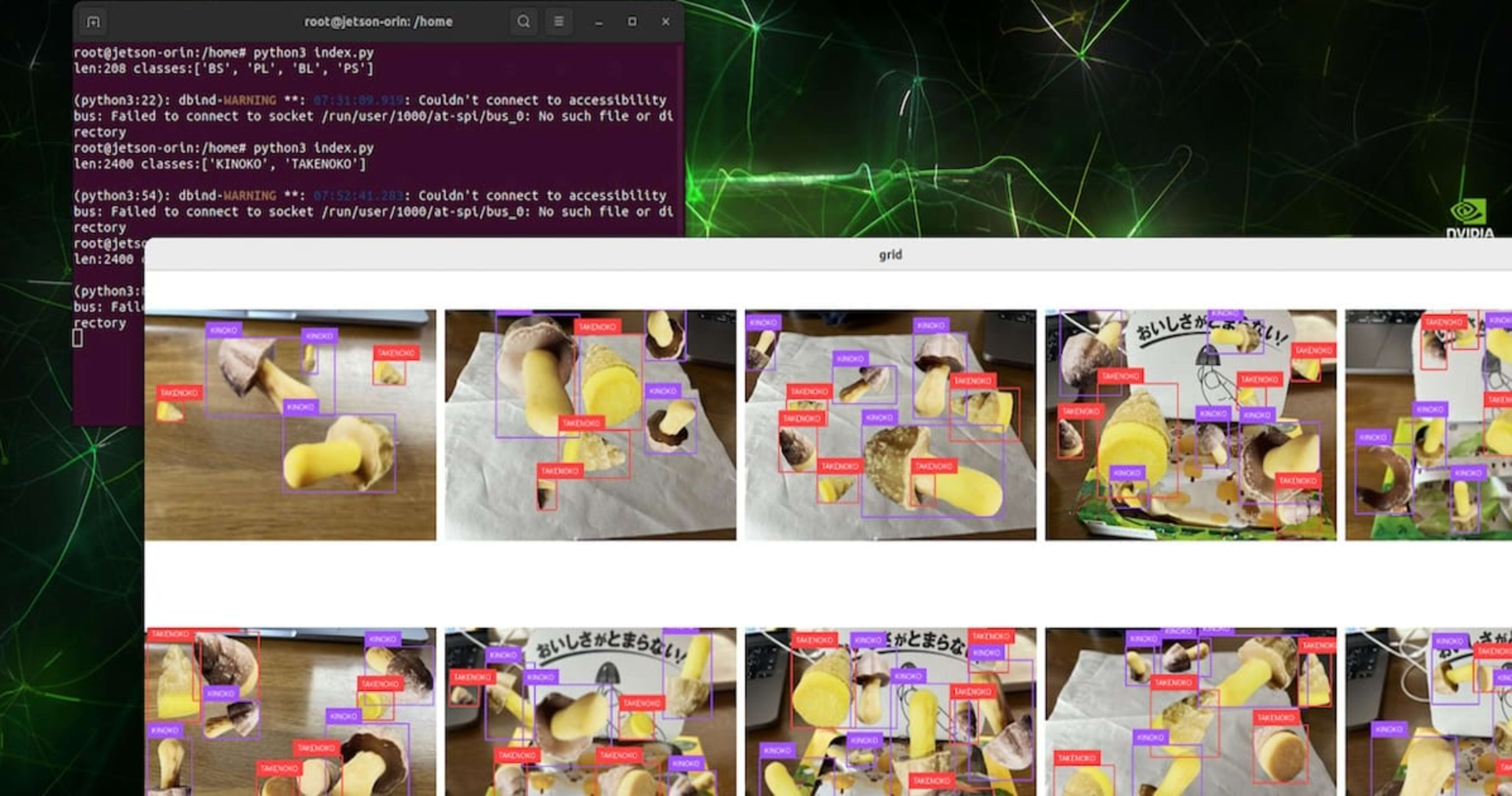
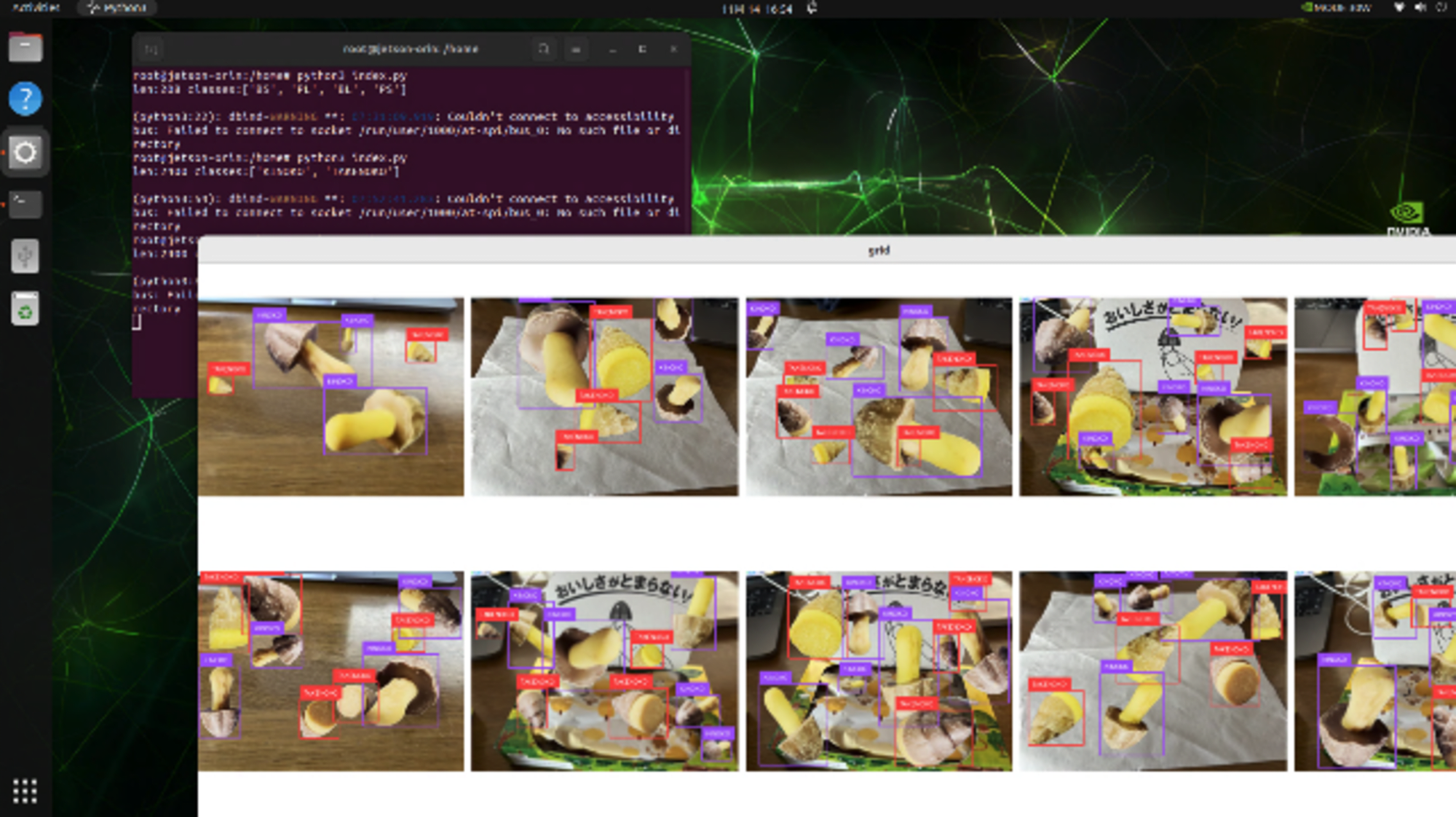
「きのこ」と「たけのこ」の検出で作成したデータセットを表示している様子です。

4 注意
APIのドキュメントDatasetsを確認する限り、今回のようにローカルのデータセットを読み込むという処理は、現時点(2024/11/16 Version0.25.0)で、「検出モデル」と「分類モデル」のみ対応しているようでした。
また、いくつかのWarningが記載されていましたので、ご留意ください。

Dataset API はまだ流動的であり、変更される可能性があります。追って通知があるまでプロジェクトで Dataset API を使用する場合は、requirements.txt または setup.py で監視バージョンを固定してください。

すべての画像を一度に必要とする場合にのみこれを使用してください。データセットを画像パスで初期化し、データセット内のパス、画像、注釈に使用すると、メモリ効率が大幅に向上します。
5 最後に
精度の高いモデルを作成するためには、正確なデータセットが必要ですが、データセットを確認するためには、表示ツールも必要不可欠です。
今回、利用させていただいた Supervisionは、非常に軽易に利用できて強力だと感じました。今後の進化が楽しみです。
※ 記事内で、freebie ACの写真を利用されていただきました。